June 2nd, 2026
New

OneClickClaw - Deploy Your OpenClaw in One Click
Get your own AI agent running on a dedicated EU-hosted server in 5 minutes. Fully managed by default, with optional advanced controls for power users. Just pick a plan and go live.

Built for Speed, Simplicity & Peace of Mind
No coding or server skills required. We take care of the server stuff so you can focus on what your bot actually does. No surprises, no hidden complexity.
One-Click Deploy
Pick a plan, pay, and your bot is live. No terminal, no coding, no server setup. We handle all of it for you.
Connect Any Chat App
Telegram, WhatsApp, Web Chat, and more. Your bot talks to your audience wherever they already hang out.
Your Data Stays Private
Your own dedicated server. Nobody else can see your conversations, API keys, or bot config. Not even us.
Always Up to Date
We auto-update OpenClaw to the stable version we trust in production. Prefer to stay on a specific build? You can pin any version from your dashboard. No manual downloads, no broken installs.
Automatic Backups
Daily and weekly snapshots, completely free. If anything goes wrong, your bot and all its data can be restored in minutes.
Simple Dashboard
See how your server is doing at a glance. Start, stop, or reboot with one click. No command line needed.
Connect to Everything
Your bot works with all the major chat apps and AI models. Use whatever combination fits your needs. Use Your ChatGPT or SuperGrok Subscription.
Messanging Channels:
Telegram
WhatsApp
Discord
Web Chat
AI Models (Bring Your Key):
OpenAI
Anthropic
Grok
Gemini
Perplexity
Kimi
DeepSeek
OpenRouter
By Opening this link you'll see the webdock partner discounted prices, live on each tier Respectively: 20% off the first month on monthly billing, or the first month free on annual. Applies to both the just OpenClaw plan (Any of the 3 tiers) and the OpenClaw + ClawCrew bundle, first-time customers only.
Zencommerce - Hosted e-commerce store
Zencommerce enables businesses to launch and scale eCommerce with AI-first simplicity, lower costs, and enterprise-grade performance without the complexity of traditional platforms like WordPress or Shopify.

AI-native vs plugin-based ecosystem
Traditional platforms rely heavily on plugins and manual configuration.
Zencommerce is AI-first, enabling users to create, modify and scale their online stores without relying on any additional plug-ins.
Outcome: Faster setup, lower technical dependency, reduced operational complexity.
Security & scalability by design
Integrated security layers (including Blackwall architecture)
Designed for performance, scalability, and long-term growth.
Outcome: Enterprise-grade reliability for growing online businesses.

Seamless migration:
Easy migration from any 3rd party platform to Zencommerce
Opportunity for customers to upgrade from fragmented systems to a unified platform. Outcome: Lower switching friction and faster onboarding.
Normal Payment Gateway + Crypto based payment systems
Native support for crypto payments through Nicky https://nicky.me/ .
Enables businesses to accept modern digital currencies alongside traditional payment methods.
On-Demand Payment integrations are possible.
Outcome: Expanded payment flexibility including COD and access to global customer segments, and future-ready commerce capabilities
Competitive pricing advantage
Flexible and efficient pricing structure designed to reduce total cost of ownership compared to traditional platforms like WordPress and Shopify.
Minimizes dependency on paid plugins, third-party tools, and high transaction fees.
Outcome: Better cost efficiency, improved margins, and higher ROI for Webdock’s marketplace user’s business.
We hope you like the Marketplace - find it after logging in to the Webdock Dashboard
As we continue expanding the Marketplace, you’ll gain access to more tools, integrations, and special offers — all designed to help you launch, scale, and operate your projects more effectively.
/
Made with love by your Webdock team 💚
April 20th, 2026
Improved

We’ve been busy behind the scenes making Webdock even snappier 😇
We’ve just rolled out new private interconnects in our POPs, giving us direct paths into some of the biggest networks out there:
400G Facebook (FRA14 / FRA5 / HAM1 / CPH1)
200G Google (FRA14 / FRA5)
100G Amazon (FR5)
100G Microsoft (FR5)
In plain English: this means shorter, cleaner, and more predictable routes between our network and major cloud and content providers. That can translate into lower latency, better consistency, less dependence on public transit paths, and generally smoother traffic flow for services that talk a lot with these platforms. In other words, fewer scenic detours for your packets.
And because we apparently don’t know how to sit still, we’ve also shipped a big API v1.1 update.
Highlights include:
Fully implemented Custom Profiles in the API — you can now create custom profiles on the fly
New ability to query platform variants and resource limits, especially handy for Custom Profiles
Profile details now include a platform field, so you can see which hardware platform a profile belongs to
The WebSSH Token endpoint now returns a fully qualified URL you can use directly
Archived server snapshots can now be listed in GET /servers/snapshots
You can now deploy Library Scripts by ID directly to a server
You can also reference scripts by slug, which is a lot friendlier for humans and Terraform alike
Added the ability to cancel scheduled deletion for a server
You can now set the Web Root for a server, with optional webserver and Let’s Encrypt config updates
Added support for setting Server Identity via the API, including removing the default Webdock alias domain
You can now regenerate SSL certificates with Certbot for your main and alias domains
Locations, Images, Platforms, and Profiles no longer require authentication, making them easier to query for discovery and automation use cases
All in all: faster roads, more knobs, more levers, more automation, and more fun for people who enjoy making infrastructure do clever things.
March 19th, 2026
New

"Why so serious"?
Our intern Oliver has decided he wants to become internet famous. Against our better judgment, we handed him an old, slightly tragic server and told him to go make questionable life choices.
The result? The very first episode of Webdock Intern Adventures — a brand-new YouTube series featuring chaos, shenanigans, and the kind of IT decisions that would normally trigger a team meeting.
In this episode, Oliver attempts to install Windows 11 on the glorified potato of a server we gave him… and then game on it. Will he succeed? Will he fail spectacularly? Will the server file a formal complaint? Watch the video below to find out.
Let us know what you think — and whether we should allow Oliver to make more of these. We’re still undecided, mostly for legal reasons. 💚
Follow our youtube channel so you don’t miss future episodes of this highly questionable series.
Hope we made your day. Now back to work 😉
Webdock
February 16th, 2026
Improved
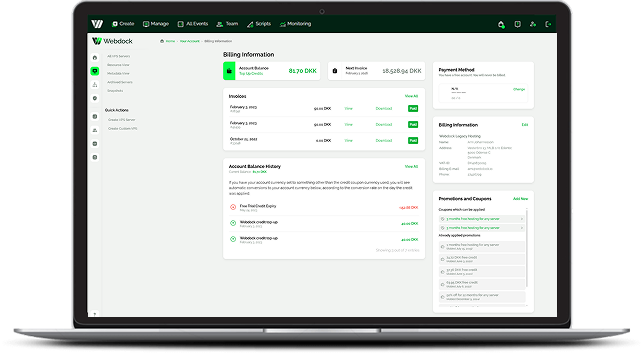
We’re excited to announce that our Webdock control panel has just received a major update. This release introduces a refreshed design, improved navigation, and several new features that make it easier and faster to manage your VPS servers.
Here’s what’s new:
🎨 New design & improved UX
The control panel has been fully redesigned with a cleaner interface and better overall usability. Navigation is now more intuitive, helping you find the tools and information you need with fewer clicks. And we still support dark mode.
🤖 Integrated AI Assistant
Our built-in AI bot can now help you troubleshoot issues, identify potential problems, and guide you toward solutions tailored to your specific VPS and configuration.

🔔 New Notification Center
All your server events and Webdock news are now collected in a single notification center inside the panel.

Coming later: server-specific alerts delivered as real-time push notifications via Firebase.
🛟 New Help Center
We’ve launched a new help center page where you can quickly get support through:
Our human support team
AI-powered assistance
Quick links to relevant documentation and guides

🧩 Upcoming SaaS Marketplace
We’re also preparing a new marketplace featuring a wide range of relevant SaaS products that integrate well with Webdock — making it easier to discover and use complementary tools for your infrastructure.
🏠 New Personalized /dash Frontpage
Soon, you’ll see a new dashboard frontpage at /dash, tailored to your specific products and services with Webdock, giving you a more relevant and streamlined overview right after login.
What’s coming next
In the coming period, we’ll continue optimizing and expanding the platform to better support your full workload — not just servers, but the surrounding services you rely on every day. We’re actively working on deeper integrations and new tooling around domains, DNS management, email services, and other complementary infrastructure features.
Planned improvements in the short run include:
The server page — making it even easier and more efficient to use
Global pages such as:
Team Members
Events
Scripts
Monitoring
These updates are part of our ongoing effort to make Webdock a more complete, streamlined, and productivity-focused platform for running your infrastructure.
As always, we appreciate your feedback.
Best regards,
The Webdock Team 💚
January 8th, 2026
New
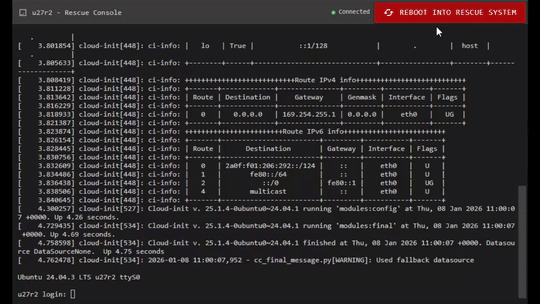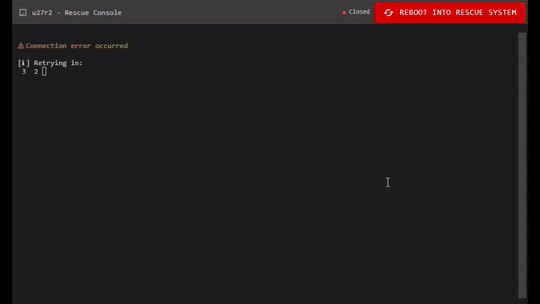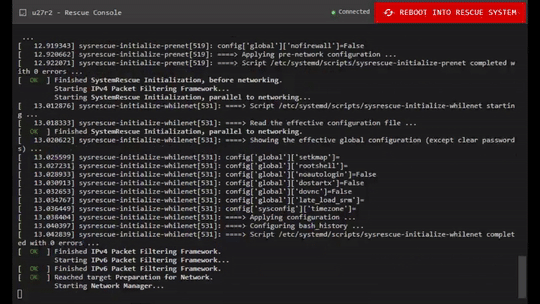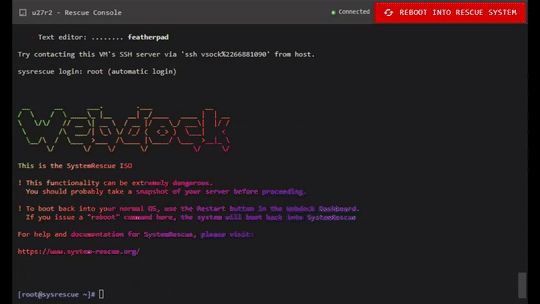
Sometimes, things break.
Filesystems get grumpy.
Bootloaders go missing.
And occasionally… you just want full, raw access to your disks without your OS getting in the way.
So we’ve just launched a brand-new feature in the Webdock Rescue Console:
👉 Reboot your VPS straight into SystemRescue — with a single click.
And yes — this feature exists because one of you asked for it just a couple of days ago. We realized it was easy to implement, genuinely useful, and honestly… a lot of fun to build. So we did. 😊
🔘 How It Works
Open the Rescue Console for your server
At the top of the screen, click “Reboot into Rescue System”
Confirm — and keep the console window open
That’s it. Your server will reboot and boot directly into the SystemRescue ISO.
It may take a minute, so please be patient while it loads.
You’ll see this message when confirming:
Reboot into Rescue System
You are about to reboot your server into SystemRescue (system-rescue.org).
Simply keep this console window open and you will see your system boot into the Rescue System ISO. This may take a minute, so please be patient.To revert to booting from your normal OS, simply use the restart button in the Webdock Dashboard.
If you issue arebootcommand inside the Rescue System, your server will simply boot back into the Rescue System.Networking should come up and be functional in SystemRescue once booted, but if you have connection issues please see the instructions in our documentation.
⚠️ Warning: Making changes to your system — especially disk partitions — is fraught with danger. You should probably create a snapshot of your server before proceeding.
🛠️ What Can You Do with SystemRescue?
SystemRescue is a powerful, battle-tested Linux rescue environment, giving you full control over your server — even if your OS won’t boot.
Here are just some of the things you can do:
💽 Disk & Filesystem Recovery
Repair broken filesystems (
fsck,btrfs-progs,xfs_repair)Mount disks manually and recover critical data
Resize or inspect partitions
Fix corrupted UUIDs or missing mounts
🧰 Boot & OS Repair
Reinstall or repair GRUB
Fix broken
/etc/fstabChroot into your installed OS for deep debugging
Recover from failed kernel upgrades
🔐 Password & Access Recovery
Reset root or user passwords
Fix broken SSH configurations
Recover access if you locked yourself out
🧪 Advanced Maintenance
Clone disks or partitions
Perform offline backups
Inspect SMART data
Zero, wipe, or securely erase disks
In short: if your OS can’t help you, SystemRescue can.
⚠️ Important Reminder
SystemRescue gives you full, unrestricted access to your disks.
This is incredibly powerful — and potentially destructive.
📸 Always create a snapshot before making changes, especially when:
Editing partitions
Repairing filesystems
Reinstalling bootloaders
🌐 Networking
Networking should come up automatically once SystemRescue has booted.
If you do experience connectivity issues, please check our docs for assistance:
👉 https://webdock.io/en/docs/webdock-control-panel/getting-started/rescue-console
🔁 Getting Back to Your Normal OS
Use the Restart button in the Webdock Dashboard to boot normally again
⚠️ If you run
rebootinside SystemRescue, your server will simply boot back into SystemRescue
💡 A Final (Friendly) Warning
SystemRescue gives you immense power — and with that comes risk.
Disk and partition changes are irreversible.
📸 We strongly recommend creating a snapshot before you begin.
As always:
You ask → we build → you break things safely 😄
Happy rescuing,
The Webdock Team 🚀
December 10th, 2025
New
We recently launched our new in-house AI chat system, and while our newsletter announcement focuses on the user-facing experience, this post goes all-in on the technical foundation. If you're curious about how a small team can design a fast, sustainable, and highly reliable RAG-powered AI assistant with full control, this is your deep dive.
Want to check it out? Try it here
Let’s start from the top and walk through the entire pipeline.
1. Architectural Overview
Our AI system is built as a modular, multi-stage pipeline optimized for speed, determinism, and Webdock-specific accuracy.
The flow looks like this:

This architecture gives us:
predictable latency
extremely high context relevance
minimal hallucination rate
full transparency and debuggability
We’re not relying on a monolithic LLM to “figure everything out.” Instead, every stage has a clear responsibility and failure domain.
2. Step 1 — Query Normalization with Mistral-Nemo
Most RAG pipelines skip this step. We do not.
Users write messy things. They ramble. They include multiple questions in one sentence. They mix languages in the same sentence. They mention emotional context, or reference “that thing earlier” without clarity.
Before we do anything, the user message is fed into a lightweight Mistral-Nemo model running locally. Its job:
Clarify ambiguous phrasings
Remove filler words
Convert casual speech into structured intent
Extract the core problem statement
Produce a version of the question optimized for vector search
Translate the query to english with high accuracy, even if mixed languages are used
This is not rewriting for the LLM — it is rewriting specifically to improve retrieval accuracy while normalizing the query to english.
Typical example:
User:
“Hey, so I rebooted and now MariaDB doesn't start and the VPS seems weird??”
Normalized version:
“MariaDB won't start after VPS reboot”
This improves retrieval precision dramatically, especially across large or similarly-worded documents.
Latency for this step: ~400 ms.

3. Step 2 — High-Performance Vector Search (bge-m3 + Markdown Knowledge Graph)
We chose bge-m3 after benchmarking several embedding models for:
semantic quality
multilingual capability
robustness to noise
cosine similarity distribution consistency
performance on small hardware
It consistently produced the best retrieval results for Webdock’s knowledge domain.
Our Knowledge Graph: Markdown Everywhere
Every piece of Webdock documentation — website pages, KB articles, product pages, FAQ entries, migration guides, pricing descriptions, API docs — is continuously transformed into clean, structured Markdown objects.
Each Markdown block is summarized into:
A short “semantic header”
A long-form chunk
Metadata tags
Canonical source URL
Timestamped summary
This gives us a search index that always matches reality, even when we update the docs.
Knowledge Base → Markdown → Summaries → Embeddings → FAISS Index
----------------------------------------------------------------
[Docs] --> [Markdown] --> [Chunking] --> [Summaries] --> [bge-m3 Embedding]
| | | |
| | | +--> [Vector Store]
| | |
| | +-----------------------> [Metadata Index]
| |
+----------------------------------> [Continuous Updater (Cronjob)]Embedding & Search
Emb → embed with bge-m3 (1024-dim vectors)
cosine similarity search using an optimized FAISS pipeline
approximate kNN tuned for sub-millisecond distance calculations
Retrieval time: ~300 ms for the entire operation, including:
embedding
vector search
top-k filtering
deduplication
relevance weighting
chunk aggregation
This is extremely fast for a full RAG pipeline.
4. Step 3 — Context Assembly + 3-Turn Memory
Once the relevant chunks are found, we build the payload for the LLM.
Included in the final context:
our engineered system prompt
the normalized query
the top relevant Markdown chunks
the user’s last 3 messages
the LLM’s most recent answer
We call this our micro-conversation memory.
It avoids long-context bloat while still supporting:
conversations about troubleshooting
multi-turn clarification
follow-up questions
refinement loops
We do not store or log this memory beyond the active session — it is purely local context.
Context assembly time: ~20–40 ms.
Context Assembly Payload Composition
System Prompt | ████████████████████ 35%
RAG Chunks | ███████████████████████████ 45%
User Message History (3 turns) | ████████ 15%
Assistant Last Reply | ██ 5%5. Step 4 — Response Generation Using Two Qwen 14B Instances
We run two independent Qwen 14B models via Ollama on GPUs. Why two?
improved throughput
better concurrency
more predictable latency
simple load balancing
Each Qwen instance is pinned to:
40 dedicated CPU cores (for tokenization + inference scheduling)
two A100 GPU tiles
With two independent pipelines, even if one instance receives a heavy prompt, the other keeps the system responsive.
Why Qwen 14B?
After extensive testing against other 3B–70B models, Qwen 14B hit the sweet spot:
excellent reasoning
strong multilingual capability
robust adherence to structured prompts
low hallucination rate
outstanding performance per GPU watt
fits comfortably on 2x A100 16GB VRAM
With our optimized prompt and RAG setup:
First Token Latency: ~3 seconds (when warm, the occasional cold startup can create +8 second latency here - we are working on eliminating that)
Streaming Speed: ~35–50 tokens/sec (varies by context size)
This is more than enough for support-grade responsiveness.
Why Ollama?
stable
predictable model loading
minimal overhead
zero dependency hell
efficient VRAM usage
trivial multi-instance support
It lets us keep everything reproducible and transparent.
6. Step 5 — Load Balancing & Concurrency
We use a simple, elegant round-robin router instead of a stateful queue.
Because the two LLM instances are truly independent, this lets us:
evenly distribute workload
avoid queue pile-ups under sudden load spikes
serve 10–12 simultaneous requests with comfortable latency
- But even if we hit those limits, we built a queue system which informs the user that they are next in line to be served :)scale horizontally by simply adding more model instances
This architecture is trivially scalable.
If we want:
4 Qwen instances?
or 8?
on multiple GPU servers?
…we can do that without rearchitecting the system.

7. Sustainable Compute: Why We Chose Refurbished A100 16GB GPUs
Our entire AI system runs on refurbished enterprise hardware:
NVIDIA A100 16GB PCIe cards
older generation, extremely affordable on the refurb market
far from “obsolete” in real-world inference workloads
A100 16GB still excels at:
medium-size LLMs (14B–30B)
multimodel pipelines
fast embedding generation
high concurrency inference
Because the models are so efficient, we need only four GPUs to serve our typical load with plenty of headroom.
Environmental Benefits
Refurbished Hardware = Less e-waste
100% Green Electricity (Denmark)
Zero cloud dependence
On-prem inference → no data shipped externally, 100% GDPR compliance
Extremely low operational power draw
This gives us a uniquely eco-friendly and privacy-oriented AI architecture.
8. Frontend: A ChatGPT-Class Experience, But Integrated Deeply into Webdock
Because we control the frontend entirely, we built features that SaaS chat solutions can’t offer:

✨ Features in our custom chat UI:
Smooth ChatGPT-style streaming
Animated typing indicator
Session history and reset controls
Suggested follow-up actions generated automatically
Human support handover button inside the chat
instantly switches to real support when needed
UI theme integrated with Webdock brand
Fine-grained analytics without compromising privacy
The entire frontend is loaded via a lightweight iframe overlay, allowing us to embed it anywhere on webdock.io or the control panel.
9. Prompt Engineering: The Backbone of Accuracy
Our system prompt enforces:
strict product scope
RAG-only factual grounding
competitor exclusion rules
escalation logic
URL constraints
multilingual replies
structured, modular response blocks
safety rules & fallback behaviors
The system prompt is the “constitution” of the AI.
It ensures:
🧭 predictable behavior
🚫 zero hallucinated services
📐 clear, structured answers
🔒 no drift into topics we do not support
😊 relatable and friendly Webdock tone
The prompt was refined through hundreds of test cases, and we continuously improve it by monitoring real user interactions.

10. Observed Performance in Production
After several weeks of testing and now a few days of real traffic:
Latency stats (p95):
Query Normalization | ██████████████████████████ 400 ms
Embedding + RAG Search | ████████████████ 300 ms
Context Assembly | ██ 35 ms
LLM First Token (warm) | ██████████████████████████████████████████████████ 3000 ms
Tokens/Second | 35–50 tokens/sec (streaming)Hallucination rate: Near zero, thanks to strict RAG reality rules.
Uptime & reliability:
Stable across thousands of user prompts.
GPU utilization:
~20–40% per 2x GPU when processing a typical single prompt — leaving plenty of headroom.
11. Why Build All This Instead of Using an Off-the-Shelf AI Service?
Three reasons:
1. Accuracy, Control & Lower latency
We cannot rely on a general-purpose AI model “hoping” it knows Webdock’s offerings.
We need deterministic grounding.
Our LLM is extremely fast: Latency to first token from submitting your prompt to the answer streaming back to you being around 3 seconds is amazing compared to most 3rd party services.
2. Performance & Cost
Running on refurbished hardware is dramatically cheaper than cloud LLM APIs at scale. All we pay for is our 100% green electricity, and our chat AI uses about 500 watts total on average, or about 12Kw/day. At average Denmark electricity costs, we are spending about 1.6 Euro/24 hours running our stack, where we could in theory handle something like 15-20 thousand queries per 24 hours - not that our load is anywhere approaching those numbers :)
Given the typical bill from our 3rd party provider we used up until this point, which used OpenAI models, we are already saving ~80% on our monthly inference costs and have a long way to go before our costs will ever increase (given the high volume we can handle already). We are no longer paying per-token or per-conversation - instead we just have to look at overall throughput / watt and how many GPUs we have available in-house.
This calculation does not take into account depreciation cost for the hardware we sourced, but we were lucky to get our hands on a large-ish stack of Enterprise Dell 4x A100 16GB machines for very cheap, so we are not really worrying about that.
3. Privacy & Sustainability
Customer queries never leave our datacenter. 100% GDPR Compliance.
12. The Future Roadmap
We’re just getting started. What we are working on in 2026:
Conversational billing explanations
Proactive troubleshooting suggestions
Embeddings and RAG for internal support tooling
Auto-generated configuration snippets
User-specific contextual help in the dashboard
Multi-agent pipeline for pre-sales + technical assistance + lifecycle management
Our current infrastructure is flexible enough to support years of expansion, and we already have the hardware on hand to build and run most of these up-coming workloads.
In Summary
Webdock’s new AI assistant is the result of an end-to-end engineering effort involving:
model tuning
careful RAG architecture
GPU optimization
environmental sustainability
frontend development
prompt engineering
concurrency control
and deep integration into our existing documentation workflows
🌩️ It’s fast.
🎯 It’s accurate.
🌱 It’s green.
🏗️ It’s ours — built by Webdock, for Webdock customers.
Thank you for reading all the nerdy details! :)
Arni Johannesson, CEO Webdock
November 20th, 2025
Improved
Smarter, Faster, and More Intuitive Than Ever
We’re excited to unveil version 2.0 of the native Webdock Control Panel app — completely redesigned to give you a faster, smoother, and more powerful way to manage your servers on the go.
Built from the ground up with an all-new user experience, this update brings a modern, intuitive interface along with a range of highly requested features that put full control of your Webdock environment right in your pocket.
Available now for iOS and Android.
🔔 Real-Time Notifications
Stay informed with push notifications for important server events. Later this year we will update the notification center with system updates, and account-related alerts — so you're always in the loop. More on that later…😀
/

💬 In-App Chat Support
Need help? Chat directly with our support team from within the app. Get quick answers and real-time assistance whenever you need it.

🚀 Create Servers On the Go
Spin up new servers in just a few taps. Whether you're launching a project or scaling up, you can now deploy new instances right from your phone.

📰 Stay Updated with the Latest News
Get the latest Webdock news, updates, and feature releases delivered straight to your app — so you never miss out on what's new.
🌙 Dark Mode
Enjoy a sleek new dark mode that’s easier on the eyes, perfect for late-night sessions or those who prefer a more subdued interface.

A New Level of Mobile Control
Webdock App v2.0 is more than just a fresh coat of paint — it’s a complete overhaul designed to make your VPS server management experience effortless, responsive, and enjoyable.
September 30th, 2025
New
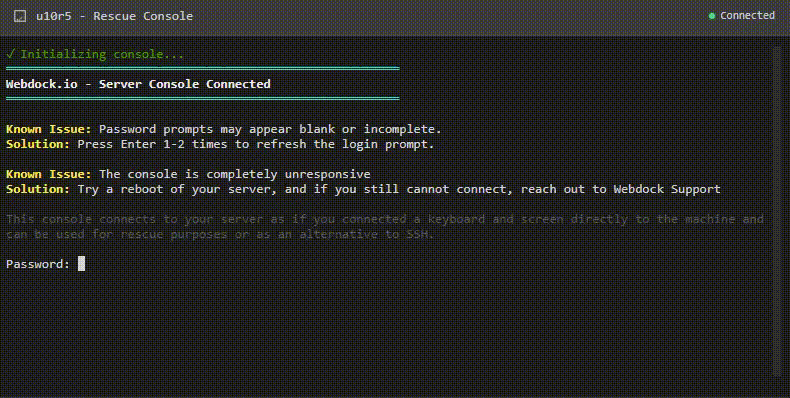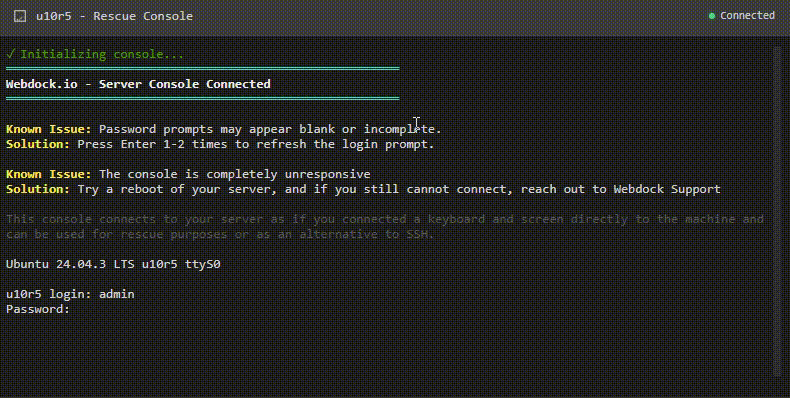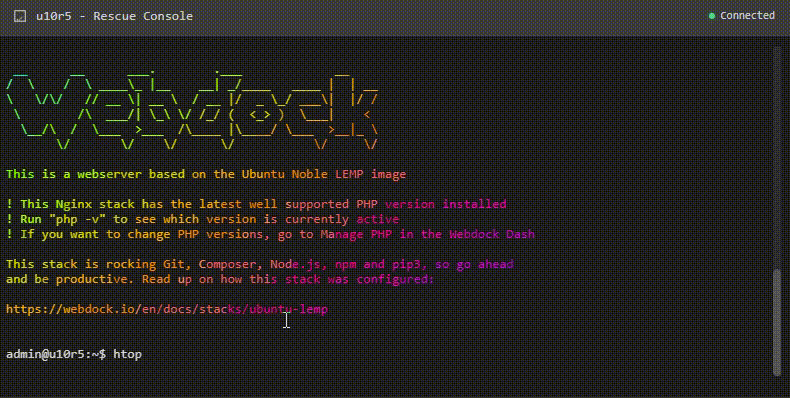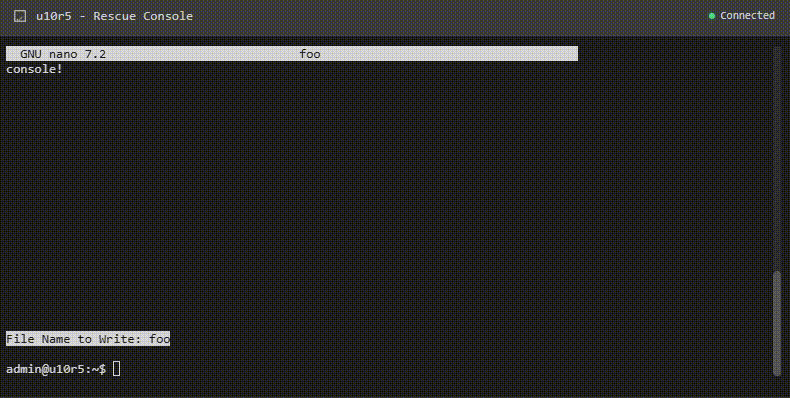
We’re excited to introduce a powerful new tool now available in your Webdock dashboard — the Rescue Console.

With Rescue Console, you can connect directly to your VPS — completely bypassing the network stack. This gives you:
Direct console access to your server, just like plugging in a monitor and keyboard.
A reliable fallback when Web SSH isn’t responding.
Rescue and recovery options for firewall lockouts, broken configurations, or network issues.
The Rescue Console is designed to give you greater control, confidence, and peace of mind when managing your servers — especially during those critical moments when every second counts. Instead of waiting on support or being blocked by networking issues, you always have a direct line into your VPS.

⚠️ Good to know: You’ll still need a working shell user login to access your server. In most cases, adding a new shell user through the Webdock dashboard will let you log in through the Rescue Console if you forgot your password or don’t have a shell user set up yet.
With this feature, we’re closing the gap between affordable VPS hosting and enterprise-grade recovery tools — putting more power back in your hands.
We have written a more detailed article in our documentation if you want to read further on how this works.
August 6th, 2025
New

The Webdock No-Nonsense Load Balancer is a powerful, flat-rate solution designed to distribute traffic evenly across multiple servers — ensuring high availability, faster performance, and automatic failover. Priced at just €9.95 per domain/month with no hidden fees, it includes SSL offloading, HTTP/3 support, edge caching, and live traffic stats — all managed through the Webdock dashboard. Hosted in Denmark with full GDPR compliance, it offers sustainable, EU-based infrastructure powered by renewable energy. Whether routing traffic to Webdock VPS or external servers, it’s a scalable, secure, and contract-free way to keep your web applications online and performing at their best.
🧰 Key Features
Flat-Fee Pricing
At €9.95 / domain per month, there are no bandwidth or request limits, and no hidden overage charges.Traffic Distribution & Redundancy
Ensures even distribution of incoming traffic across multiple servers, reducing overload, latency, and downtime. Automatic failover reroutes traffic if one server becomes unavailable.Performance Enhancements
Offers SSL offloading, HTTP/3 support, edge caching of static and dynamic content, and can reduce server load by up to 25%.Security & EU Hosting & Sustainability
Hosted in Webdock’s Denmark data centre (DK‑DC1), with GDPR compliance and multi-layer protection including Voxility DDoS scrubbing. Infrastructure runs on renewable energy.Integrated & Simple Setup
Easily created and managed via the Webdock control panel. Includes automated Let’s Encrypt SSL certs, DNS configuration instructions, and live traffic stats. Fits alongside other Webdock services in a unified dashboard.Scalability & Flexibility
Designed to adapt to traffic spikes transparently. Can route traffic to both Webdock VPS and external servers with full control over hardware and IPs—no vendor lock-in, no contracts.
✅ Why Webdock’s Load Balancer?
Fixed, predictable monthly cost per domain.
Improved performance and uptime with effortless scaling.
Seamless integration with Webdock's existing VPS ecosystem.
European-hosted, privacy-conscious, and energy-efficient infrastructure.
August 6th, 2025
New
Introducing the Webdock No-Nonsense Web Application Firewall — a powerful, EU-hosted security solution designed to protect your websites from bots, scrapers, DDoS, and other malicious attacks. Built on the advanced Blackwall engine, this WAF offers real-time protection without the need for complex setup or manual rule management. With flat-rate pricing, seamless integration into your Webdock dashboard, and GDPR-compliant hosting in Denmark, it’s the ideal choice for developers and businesses who want reliable, hassle-free website security. Activate per domain, customize as needed, and enjoy faster load times with less server strain — all without vendor lock-in or hidden costs.
Key Features
Advanced Protection: Blocks bots, scrapers, SQL injections, XSS, Layer-7 (L7) DDoS attacks using the BotGuard/Blackwall engine—no manual rule setup required.
Effortless Management: Activate protection per domain via the Webdock dashboard. DNS configuration and SSL certificate handling via Let’s Encrypt are included.
Pricing & Billing
Flat-Rate Pricing: €11.95 per domain/month, with no bandwidth limits, overage charges, or hidden fees.
Data Sovereignty & GDPR Compliance
Datacenter in Denmark (DK‑DC1): Fully owned and operated by Webdock, ensuring data remains within the EU under strict EU law.
No Vendor Lock-in: Full freedom to use your stack or switch providers at any time, with no contracts.
Performance & Integration
Performance Optimisation: Mitigates malicious traffic to reduce server load and improve response times.
Unified Dashboard Experience: Manage WAF alongside SSL, caching, load balancers, and VPS within Webdock’s control panel.
Scalable Cloud Architecture: Automatically handles traffic spikes and scales with your domain needs.
Security & Maintenance
Regular Updates: Constant updates of threat signatures and security logic ensure protection against the latest attacks.
Customizable Rules: Tailor firewall behavior per domain for more precise security control.
✅ Why Choose a Web Application Firewall?
Effective protection against bots, DDoS, scrapers, and automated attacks.
Low server load, faster page delivery.
Simplified pricing model with predictable monthly costs.
Full EU data control thanks to a Danish data centre.
Integrated with Webdock’s ecosystem—easy setup, unified management.
🚀 Getting Started
Activate via Dashboard: Add your domain, then follow DNS configuration instructions.
System Setup: WAF filters traffic, issues SSL, and enables edge caching automatically.
Monitor & Customize: Access detailed traffic metrics and tweak rules as needed.
Unified Billing: View charges alongside other Webdock services—all within the same account.
In summary, Webdock’s No‑Nonsense WAF delivers high-performance, EU‑based web application firewall functionality with transparent pricing, minimal maintenance, and tight integration into the Webdock ecosystem.